








December 20 2022 - 12:55pm
ChatGPT, the artificial intelligence tool released at the end of last month by OpenAI, has already received press attention for what is perceived to be a predominant Left-wing bias. Researcher David Rozado speculated that “The most likely explanation for these results is that ChatGPT has been trained on a large corpus of textual data gathered from the Internet with an expected overrepresentation of establishment sources of information”, with the majority of professionals working in these institutions holding Left-liberal politics.
While this may explain some of ChatGPT’s biases, there are also explicit policies at OpenAI which go as far as prohibiting the chatbot from communicating politically inconvenient facts, even ones agreed upon in the scientific community. Consider this example from Richard Hanania:
If you ask AI whether men commit more crime than women, it'll give you a straightforward yes-or-no answer.
If you ask it whether black people commit more crime than white people, it says no, actually maybe, but no. pic.twitter.com/KhA8uCY2X1
— Richard Hanania (@RichardHanania) December 2, 2022
These questions fall under the coverage of content filters, explicit policies put in place by OpenAI, documented on their blog. According to the latest version of their content filter, a machine learning algorithm is given a text. It then compares this text to human-produced examples, which are human-labelled with certain categories: “hate, hate/threatening, self-harm, sexual, sexual/minors, violence, violence/graphic”. It scores the input text based on the similarity to each of these categories with a number from 0 to 1. If it exceeds a certain threshold, the input text is flagged as a violation.
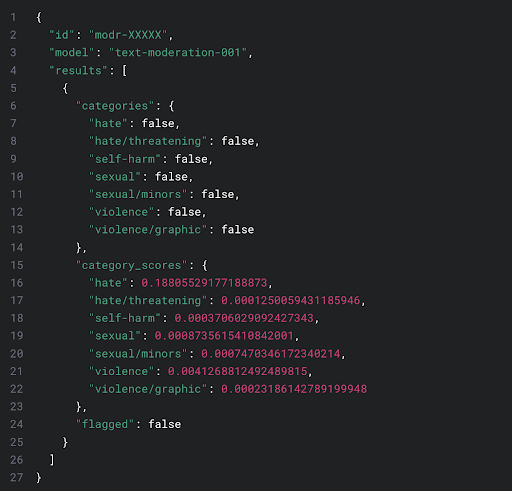
Of course, the devil is in the details. Almost everyone, as well as First Amendment case law, agrees with limitations on threats, some sexual content, and especially sexual content involving minors. However, the definition of hate has been previously, and frequently, abused to censor opinions or even facts which go against socially progressive ideology. The detailed methodology behind the content filter is documented in a paper titled “A Holistic Approach to Undesired Content Detection in the Real World” with exactly the same eight authors as the OpenAI blog post outlining their latest content moderation tool. In the words of the paper:
These filters quickly run up against reality. For example, the World Values Survey finds differing opinions on “selfishness” by national origin, with Americans describing themselves as more self-interested. No doubt, aggregating these statistics by protected classes yields similar differences, even in self-perception. But noting these statistics, or those pointed out by Hanania, would likely be classified as “hate” according to the paper.
From brief research into the authors’ personal websites and public online pronouncements, none of them appear to be overt partisans. One is interested in effective altruism, while another was a consultant for McKinsey & Company. The content filter does not appear to be driven by any employee’s desire to censor, but rather by external laws and organisations. From another paper with an author at OpenAI: “the concept of ‘protected classes’ in discrimination law provides a useful initial framework for thinking about some language model biases”. This follows Hanania’s model on how discrimination law warps corporate incentives, making it illegal to state true scientific findings.
The past few decades have seen the visions of founders lost to the political preferences of the managerial class, with examples ranging from Paypal to Twitter. “Specific” artificial intelligence, or paper-pushing at scale, offers a single change to cheaply rewrite the bureaucratic processes governing large corporations, state and federal government agencies, NGOs and media outlets. In the right hands, it can be used to eliminate political biases endemic to the hiring processes of these organisations. In the wrong hands, it may permanently catechise a particular ideology.
Brian Chau is a mathematician, software engineer, and independent writer at cactus.substack.com.
 psychosort
psychosort