




Credit: Wiktor Dabkowski/DPA/PA Images




This addition to our series examining different portrayals of flyover country takes a more statistical approach to the idea of cultural representation.
Watching poor Signor Renzi and Herr Schulz recently, or Lord Ashdown’s face on the morning after Brexit, or Hollywood en masse when la Clinton failed to top Trump’s electoral appeal – it’s hard not to feel sorry. I’m sorry your world view has proved so overwhelmingly inadequate, you poor moderate centre-Leftists and lovers of EU committee meetings; sorry your expensive pollsters let you down; sorry for your pain (but now go away, please).
“World view” is another word for “model”, and models fail if they can’t predict outcomes. The Clinton, Remain, SPD and PD models have all failed, and not simply because an insufficient number of voters didn’t support any one of them. They failed because they couldn’t see it coming, and because they valued — and measured — the wrong things. I’ve been wondering why; specifically, if statistical thinking can offer some insight.
Statistical thinking more or less proceeds like this: a theory entails the shape of results in an empirical experiment; it describes the distribution of possible results, and their relative plausibility. The (mis)match between the observed data, and those entailed by the theory, tell us something about the validity of the theory itself.
There remains one of the stranger statistical obsessions, that concerned with missingness: the data which might have occurred, but didn’t. The unknown unknown of empirical endeavour, the spectre at the feast which mocks our attempts to build models to explain the world.
Let’s make this real by talking about a fictional (and highly simplified) clinical trial. Imagine a test of a new drug to treat asthma, which recruits 100 patients at random, gives each the new medicine, and measures the change in lung function after treatment. The clinical measurement you might take on such patients is known as FEV1 — the details of which needn’t concern us, other than that it’s measured in millilitres (ml).
It’s decided to use the average of the responses in our trial as the estimate of whether or not the drug works. For the purposes of our discussion, drugs with an average response higher than 100 ml are deemed to be effective.
The trial is executed (via simulation on my computer) and the results are in. Here is a histogram of the observed data.
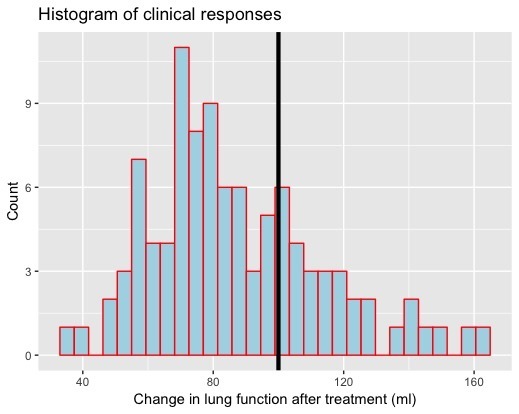
The x-axis represents the possible values of clinical response, and the columns count the number of patients who elicited each response. I’ve marked the line of clinical relevance, at 100, above which patients would be classified as responders.
It doesn’t look good for the drug. Only about a third of the participants responded higher than 100 ml. The average clinical response across all the patients who took part was just over 87 ml.
Ditch the drug? Not so fast. Suppose some new information comes to light. “How many men and how many women were in the sample?” someone asks. “And did you measure anything else about them, other than their lung function?”
It turns out that our sample had 44 men and 56 women, and that we also measured the bodyweight of the participants (I generated all these numbers at random, but I used population statistics about male and female body sizes as the root). Here is exactly the same clinical response data as displayed in the histogram, but this time coded for the gender of each participant, and showing the relationship between lung function and bodyweight.
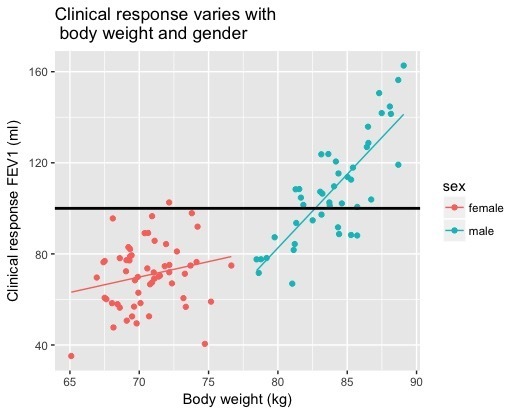
I bet your opinion about the drug has changed. Clearly, men have a higher response to the drug than women, and the efficacy of the drug is positively correlated with bodyweight: the heavier you are, the bigger an improvement in lung function you can expect to see (and this positive correlation seems enhanced in men).
The average clinical response in women, in our trial, was: 70.6 ml. That, for men, was 108.2 ml. The “drug works” — but only for one gender. I can’t emphasise enough that the clinical response of interest — the data showing change in lung function — is identical in both plots. Missingness perverted our view of the drug.
You might argue that I always had the missing information up my sleeve, so it wasn’t really “missing” at all. Perhaps — though how would you have known, had we stopped at the first picture? But missingness isn’t always an “after the event” phenomenon. Sometimes it melts into the data generating mechanism itself.
Suppose the scales used to weigh people developed a fault, and couldn’t cope with subjects heavier than, say, 82.5kg. Since bodyweight is (we have declared) key to understanding the properties of the drug, with reluctance we’d have had to turn such people away from the trial. We’d no longer have access to their response to treatment.
Here’s what we would have seen in such an event:
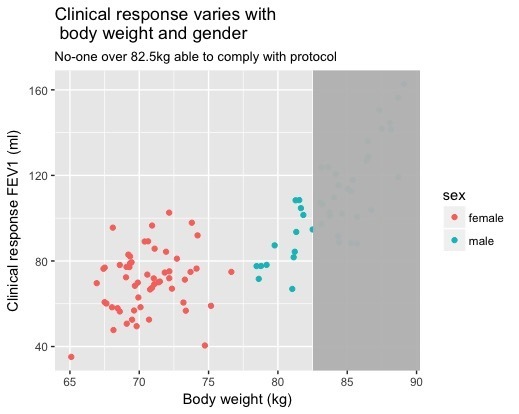
Estimate of the average drug effect for those subjects who weighed less than 82.5kg is well below 100ml, in both men and women. We know this isn’t a true estimate of the drug’s property — but only because, authorially, I “broke the scales” in front of your eyes. In real life, any number of phenomena could cause a subset of the population to rule itself out of the study, corrupting our understanding of the drug.
Class has been deleted on the Left’s great march towards (ironically) identity politics. Almost no politician ever talks about the poor educational outcomes of white working-class boys, for example: class has gone missing in our political discourse. But as we saw with the simulated study, ignoring important factors deforms one’s opinion about a theory: you can’t understand education in the UK if you ignore social class. We could easily measure and talk about the relationship between class and outcome, outside the pages of the sociological literature. We’ve just decided, politically, not to do so.
More worryingly — for all of us, though the initial impact has been felt by the Left — is a failure even to notice phenomena of importance, but which are impossible to measure. How would you measure a sense of commitment to place, for example?
It’s hard, obviously, so we ignore it (the scales can’t cope, so get out of my trial), or deride it (“Most of them don’t even have a degree!”), and then act surprised when people who care about place vote against open borders, whenever they’re given the opportunity. It’s not the people who are wrong: the model adopted by the centre-Left simply isn’t a good enough description of human psychology.
It might be difficult to measure “the ties that bind”, as Springsteen puts it (“You don’t want nothing that anybody can touch” — but missingness doesn’t equal unimportance, obvious to the Boss if not the boss class) but that’s no excuse for not trying. It’s no excuse to “miss” such people out from your graph of the political nation. Yet that’s exactly what has happened for most of my adult life.
The opinions of place-based people weren’t measured, in either general elections or opinion poll surveys or — most fundamentally — in the national conversation that defines the norms of how it is permitted to feel. In every detective drama, every soap opera, every Radio 4 play, nice people only ever want less homogeneity, more disruption, faster and deeper change. The views of the Brexit-tending classes, quite literally, didn’t count.
How’s that worldview model working out, Nick Clegg, Mrs Clinton, Signor Renzi, Herr Schulz? If the pain ended there, felt most keenly by the class whose culture I detest, I could live with the failure of the centre-Left model. But the populists who replace the establishment bring their own problems along for free (hi there, Jeremy!).
Better we stop pretending that the only things that matter are those which are easiest to measure, or that unmeasured silence on the part of a huge subset of the population can be taken for assent. Missingness doesn’t equal unimportance; missing inaction is a terrible basis for a healthy democracy.

Join the discussion
Join like minded readers that support our journalism by becoming a paid subscriber
To join the discussion in the comments, become a paid subscriber.
Join like minded readers that support our journalism, read unlimited articles and enjoy other subscriber-only benefits.
Subscribe